Caching is a common technique for reusing some computation
It can speed up queries that use the same data
There are two functions used for caching
df.cahce()
df.persist()
Persist takes an optional argument storageLevel where we can specify the location where the data should be cached
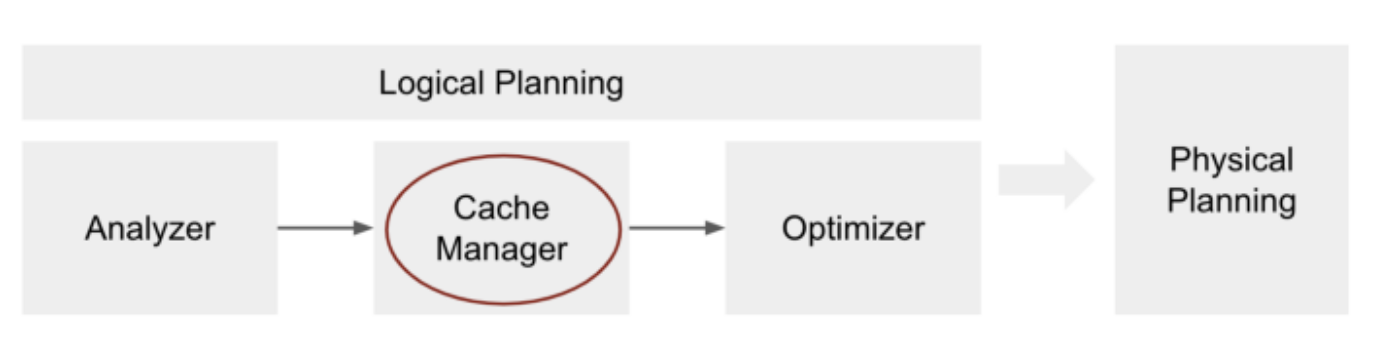
It is a lazy operation, nothing happens when it is called except that the query plan is updated by the Cache Manager by adding a new operatorInMemoryRelation
Spark will look for data in the caching layer if it's available
A query with an action will look for any analyzed plan that is stored in the same subtree which means it can be used
For a query to utilize the cached data the analyzed logical plan has to be identical but not the optimized logical plan
Best practices
Use a new variable to store the cached DF to reduce confusion
Unpresist the DF if it is not used to free up space
Cache only what you need
Retrospective::
One week ago: [[April 16th, 2021]]
One month ago: [[March 23rd, 2021]]
One quarter ago: [[January 23rd, 2021]]
One year ago: [[April 23rd, 2020]]
Daily Stoic::
Our mind is truely ours, take care of it like such